

Es gibt weltweit mehr als 180 Sprachfamilien. Doch was wäre, wenn es eine gemeinsame Sprache geben würde, über die sich alle verständigen? Viele von Ihnen werden jetzt sagen: „Ja klar, Englisch ist die Universalsprache!“. Doch die Praxis zeigt, dass nicht jeder Mensch Englisch so gut versteht oder spricht, wie es für eine „Weltsprache“ angemessen wäre.
Die Informatik ist gar nicht so verschieden. Gefühlt spricht jedes Programm seine eigene Sprache oder zumindest seinen eigenen Dialekt, wenn es um Daten geht. Eine gemeinsame Sprache wäre hier mehr als wünschenswert.
Was ist das Kanonische Datenmodell?
Linguisten würden das Kanonische Datenmodell (KDM) vielleicht als Universalsprache beschreiben. In der Mathematik kann das Konzept des kleinsten gemeinsamen Teilers als Bild für ein KDM dienen. Vielleicht könnte man das KDM als die eierlegende Wollmilchsau der Informatik bezeichnen.
Ziel eines Kanonischen Datenmodells ist es, ein möglichst einfaches, einheitliches Modell bereitzustellen, über das alle angebundenen Systeme miteinander kommunizieren können, unabhängig von den internen Datenmodellen.
„Das ist unmöglich!“, sagen Sie?
Die Informatikaffinen kennen diesen Ansatz eventuell schon. Ein Kanonisches Datenmodell zielt darauf ab, Entitäten verschiedener Systeme in einer gemeinsamen Form zu vereinen. Und das in einer Form, in der auch ein normaler Mensch die Beziehungen möglichst nachvollziehen kann.
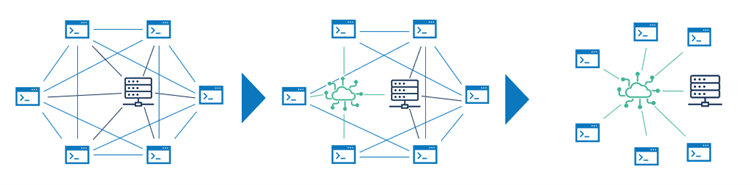
Die Idee ist so einfach wie sinnvoll. Anstatt jedes Datenmodell eines Systems mit jedem anderen Modell in Verbindung zu setzen, binden wir die Systeme nur an ein gemeinsames Kanonisches Datenmodell an. So wird aus einer 1:n-Anbindung bei einer Integration nur eine 1:1-Anbindung.
Wo ist der Haken?
Die Vorzüge eines Kanonischen Datenmodells wurden genannt. Aber wie alles im Leben, wirft jedes Licht auch Schatten. Ein Kanonisches Datenmodell erfordert viel Arbeit und viel Pflege.
Eine gemeinsame Datenbasis muss erstmal geschaffen werden und das erfordert eine ganze Menge Arbeit und Klärung. Hat System A für einen Vertrag ein Attribut “Beginn” hinterlegt, dann ist nicht automatisch klar, ob es sich hier um den formellen, materiellen oder technischen Beginn handelt. Gegebenenfalls hat System A sogar Parameter, die es in System B gar nicht gibt. Jetzt ist die Frage: „Brauchen wir dieses Attribut wirklich? Und gibt es eine Entsprechung im Kanonischen Datenmodell? Muss das Modell um dieses Attribut erweitert werden?“
Das alles erfordert viel fachliche Klärung und damit viel Zeit. Wenn dann noch x Umsysteme dazu kommen, erhöht sich nicht nur der Klärungsaufwand, sondern gegebenenfalls auch die Anzahl der Attribute, die in das gemeinsame Datenmodell aufgenommen werden müssen.
Ein Kanonisches Datenmodell für alles! Oder nicht?
Hier sind wir jetzt an dem Punkt angekommen, an dem wir uns von einem zentralen KDM für alles verabschieden müssen. Ein Modell, das so umfassend ist, wäre unkontrollierbar und würde in Dimensionen wachsen, die schlichtweg nicht mehr überschaubar wären. Und das ist einer der Gründe, warum sich in der Vergangenheit das KDM in seiner ursprünglichen Form nicht durchgesetzt hat.
Aber das heißt nicht, dass wir die grundsätzliche Idee nicht in einer abgewandelten Form aufgreifen können. Hier setzt PLATIN mit seinem mehrstufigen Entitäten-KDM-Ansatz an. Es werden Entitäten definiert und für jede einzelne Entität ein eigenes Datenmodell entworfen. Damit haben beispielsweise Partner ein grundsätzlich anders aufgebautes einheitliches Datenmodell als Verträge.
Damit werden die verschiedenen Entitäten entkoppelt. Klärungen und Änderungen können gezielter und übersichtlicher umgesetzt werden, was dem ganzen System mehr Flexibilität gibt.
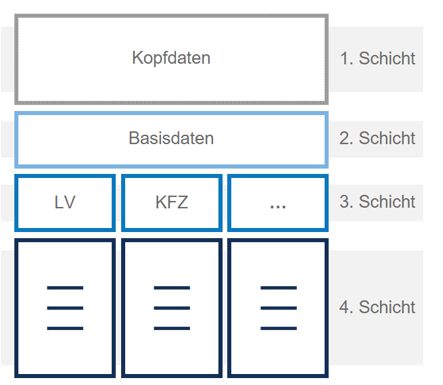
Warum werden jetzt noch Schichten in die einzelnen Datenmodelle eingeführt?
Ein einheitliches Datenmodell für Verträge muss, um den Ansprüchen eines kanonischen Datenmodells zu genügen, alle relevanten Informationen aller angebundenen Vertragsarten halten können. Das heißt aber nicht, dass jeder Vertrag jedes Attribut nutzt.
Wenn wir diese ganzen Attribute in einem einzelnen nicht in sich abgegrenzten Modell unterbringen, dann kommen wir schnell wieder an den Punkt, an dem wir ein gigantisches Konstrukt erzeugen, das unbeherrschbar wird. Aus diesem Grund macht es Sinn, dass man hier inhaltliche Abgrenzungen vornimmt, ähnlich dem “Teile-und-herrsche”-Prinzip.
Das geschieht durch eine Abgrenzung in mehrere Stufen, die mit zunehmender Stufe allgemein gültige Attribute von spezifischen Attributen trennen. So gibt es – am Beispiel Vertrag gesehen – Attribute, über die jeder Vertrag verfügt. Hier gibt es etwa die Versicherungsnummer, einen Versicherungsnehmer und ein “Gültig Ab”-Datum, wohingegen ein “Stellplatz” spezifisch für eine KFZ–Versicherung ist.
Durch diese Abgrenzung von Bereichen in den tieferen Stufen wird das Datenmodell der Entität hochgradig erweiterbar und wartbar. Zusätzlich kann verhindert werden, dass jeder Vertrag unnötig viele, nicht relevante Attribute mit durch das gesamte System zieht, denn manche Systeme interessieren vielleicht nur die allgemeinen Attribute.
Das Kanonische Datenmodell, ein alter Hut und doch so aktuell wie noch nie?
Wir leben mittlerweile in einer Zeit, in der sich Technologie-Zyklen in Jahren und nicht mehr in Jahrzehnten messen lassen, das betrifft auch den Software-Bereich. Dadurch gewinnen Worte wie Software-Integration enorm an Gewicht.
Das Kanonische Datenmodell ist in diesem Kontext keine Neuerfindung. Aber in der Vergangenheit war der Aufwand, dieses zentrale Datenmodell aufzustellen und zu pflegen, größer als der gesehene Nutzen. Durch den neuen Ansatz von PLATIN lässt sich dieser Aufwand abfedern und die Stärken beibehalten. Die wahren Stärken spielt das Kanonische Datenmodell nämlich erst dann aus, wenn man verschiedene unabhängig entwickelte Systeme versucht in seine Systemlandschaft zu integrieren. Der initiale Aufwand zahlt sich so bei jeder folgenden Integration positiv aus.
Wir freuen uns auf den Austausch und teilen mit Ihnen gerne unsere Integrationserfahrungen rund um KDM, iPaaS, Partnerschaften und Produktideen.
Melden Sie sich an zum Roundtable iPaaS; zu Themen rund um Platform Integration im Versicherungsumfeld
Freuen Sie sich auf spannende Praxisberichte, tauschen Sie sich über aktuelle Trends aus und teilen Sie gerne auch Ihre Erfahrungen.
Gastautor: Henning Lück




